DFS序
DFS序即用DFS访问一棵树时,访问节点的顺序。
比如这棵树
1 2
1 3
2 4
2 5
不妨认为号节点是根节点。
二叉树的DFS序
先序排列即先访问根节点,再访问左孩子,最后访问右孩子。
中序排列即先访问左孩子,再访问根节点,最后访问右孩子。
后序排列即先访问左孩子,再访问右孩子,最后访问根节点。
先序排列:1 2 4 5 3
中序排列:4 2 5 1 3
后序排列:4 5 2 3 1
已知中序排列,和先序排列,可以还原二叉树,并推出后序排列。
已知中序排列,和后序排列,可以还原二叉树,并推出先序排列。
但是已知先序排列和后序排列,可能无法唯一确定二叉树。
进出栈序
1 2 4 4 5 5 2 3 3 1
即进栈记录一次,出栈记录一次,每个点在序列中出现两次,序列总长度为。
子树在序列中是连续的一段,比如2 4 4 5 5 2就是原树的一段
所以这种DFS序可以用来解决 子树/单点 修改,子树/单点 询问。
如果结合树链剖分,每到一个点,先DFS重链所在的子树,那么也可以支持链上的修改和询问。
每个点等价于一个区间
- x和y相同,区间相同
- x是y的祖先,x的区间包含y的区间
- y是x的祖先,y的区间包含x的区间
- x和y没有关系,两个区间相离
区间不可能相交
欧拉序
1 2 4 2 5 2 1 3
即每访问一个点,记录一次,每个点在序列中出现度数次,序列总长度为。
一般不记录最后一次回到根节点,以满足以上性质。(否则根节点出现次数是度数+1)
欧拉序最常见的用法就是和ST结合起来求LCA。
两个点(如果一个点出现多次,任意一个均可)之间深度最浅的点,即为这两个点的LCA。
DFS序列
考虑 这样一棵树,5个点,4条边,根节点是1
1 2
1 3
3 4
3 5
DFS序有两种
进出栈序
1 2 2 3 4 4 5 5 3 1
欧拉序
1 2 1 3 4 3 5 3
欧拉序
欧拉序,每个点被访问一次,就会被记录一次
1 2 1 3 4 3 5 3
总长度
每个点出现次数 等于 自己的度数
两个点的LCA,就是两个点之间最浅的点
进出栈序
+表示进栈,-表示出栈
1 2 2 3 4 4 5 5 3 1
+ + - + + - + - - -
每个数字恰好出现次
在一些实现中,我们只存第一次出现
单点修改,查询子树之和
子树是区间
只在每个点的第一次出现加上点权
单点修改,查询一个点到根节点路径之和
这个点的第一次出现加上点权
这个点的第二次出现减去点权
查询前缀即可
参考题目
P1030 [NOIP2001 普及组] 求先序排列
https://www.luogu.com.cn/problem/P1030
题目描述
给出一棵二叉树的中序与后序排列。求出它的先序排列。(约定树结点用不同的大写字母表示,长度)。
输入格式
行,均为大写字母组成的字符串,表示一棵二叉树的中序与后序排列。
输出格式
行,表示一棵二叉树的先序。
样例 #1
样例输入 #1
BADC
BDCA
样例输出 #1
ABCD
提示
【题目来源】
NOIP 2001 普及组第三题
参考代码
#include <bits/stdc++.h> using namespace std; void dfs(string in, string post) { if (in.size() > 0) { char ch = post[post.size() - 1]; cout << ch; int p = in.find(ch); dfs(in.substr(0, p), post.substr(0, p)); dfs(in.substr(p + 1), post.substr(p, post.size() - 1 - p)); } } int main() { string in, post; cin >> in >> post; dfs(in, post); }
题解
已知 后序遍历 和 中序遍历 求 前序遍历
后序的最后一个字符,一定是根节点
已知根节点,可以把中序遍历分成左右子树两段
两段递归做
P2146 [NOI2015] 软件包管理器
https://www.luogu.com.cn/problem/P2146
题目背景
Linux 用户和 OSX 用户一定对软件包管理器不会陌生。通过软件包管理器,你可以通过一行命令安装某一个软件包,然后软件包管理器会帮助你从软件源下载软件包,同时自动解决所有的依赖(即下载安装这个软件包的安装所依赖的其它软件包),完成所有的配置。Debian/Ubuntu 使用的 apt-get,Fedora/CentOS 使用的 yum,以及 OSX 下可用的 homebrew 都是优秀的软件包管理器。
题目描述
你决定设计你自己的软件包管理器。不可避免地,你要解决软件包之间的依赖问题。如果软件包 依赖软件包 ,那么安装软件包 以前,必须先安装软件包 。同时,如果想要卸载软件包 ,则必须卸载软件包 。
现在你已经获得了所有的软件包之间的依赖关系。而且,由于你之前的工作,除 号软件包以外,在你的管理器当中的软件包都会依赖一个且仅一个软件包,而 号软件包不依赖任何一个软件包。且依赖关系不存在环(即不会存在 个软件包 ,对于 , 依赖 ,而 依赖 的情况)。
现在你要为你的软件包管理器写一个依赖解决程序。根据反馈,用户希望在安装和卸载某个软件包时,快速地知道这个操作实际上会改变多少个软件包的安装状态(即安装操作会安装多少个未安装的软件包,或卸载操作会卸载多少个已安装的软件包),你的任务就是实现这个部分。
注意,安装一个已安装的软件包,或卸载一个未安装的软件包,都不会改变任何软件包的安装状态,即在此情况下,改变安装状态的软件包数为 。
输入格式
第一行一个正整数 ,表示软件包个数,从 开始编号。
第二行有 个整数,第 个表示 号软件包依赖的软件包编号。
然后一行一个正整数 ,表示操作个数,格式如下:
install x表示安装 号软件包uninstall x表示卸载 号软件包
一开始所有软件包都是未安装的。
对于每个操作,你需要输出这步操作会改变多少个软件包的安装状态,随后应用这个操作(即改变你维护的安装状态)。
输出格式
输出 行,每行一个整数,表示每次询问的答案。
样例 #1
样例输入 #1
7
0 0 0 1 1 5
5
install 5
install 6
uninstall 1
install 4
uninstall 0
样例输出 #1
3
1
3
2
3
样例 #2
样例输入 #2
10
0 1 2 1 3 0 0 3 2
10
install 0
install 3
uninstall 2
install 7
install 5
install 9
uninstall 9
install 4
install 1
install 9
样例输出 #2
1
3
2
1
3
1
1
1
0
1
提示
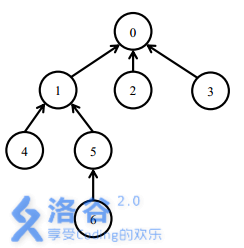
一开始所有软件包都处于未安装状态。
安装 号软件包,需要安装 三个软件包。
之后安装 号软件包,只需要安装 号软件包。此时安装了 四个软件包。
卸载 号软件包需要卸载 三个软件包。此时只有 号软件包还处于安装状态。
之后安装 号软件包,需要安装 两个软件包。此时 处在安装状态。最后,卸载 号软件包会卸载所有的软件包。
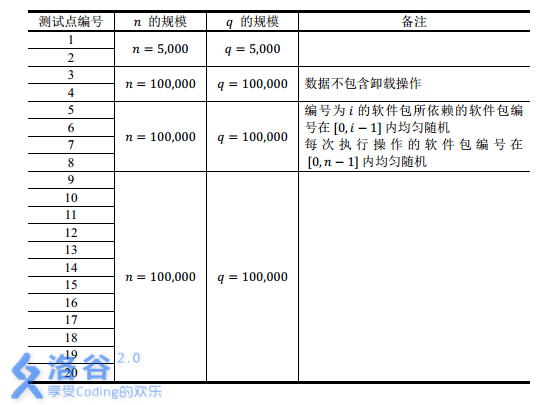
【数据范围】
参考代码
#include <bits/stdc++.h> using namespace std; int n, m; vector<int> a[100020]; int b[100020]; int f[100020]; int l[100020]; int s[100020]; int L[100020]; int R[100020]; int ss, x; int sm[400020]; int sa[400020]; void sam(int x, int l, int r, int v) { sm[x] = (r - l) * v; sa[x] = v; } void push(int x, int l, int r) { if (~sa[x]) { int mid = (l + r) / 2; sam(x * 2, l, mid, sa[x]); sam(x * 2 + 1, mid, r, sa[x]); sa[x] = -1; } } void change(int x, int l, int r, int L, int R, int v) { if (r <= L || R <= l) { return; } if (L <= l && r <= R) { sam(x, l, r, v); return; } push(x, l, r); int mid = (l + r) / 2; change(x * 2, l, mid, L, R, v); change(x * 2 + 1, mid, r, L, R, v); sm[x] = sm[x * 2] + sm[x * 2 + 1]; } int query(int x, int l, int r, int L, int R) { if (r <= L || R <= l) { return 0; } if (L <= l && r <= R) { return sm[x]; } push(x, l, r); int mid = (l + r) / 2; return query(x * 2, l, mid, L, R) + query(x * 2 + 1, mid, r, L, R); } void dfs(int x, int y) { s[x] = 1; f[x] = y; for (int i: a[x]) { dfs(i, x); s[x] += s[i]; if (!b[x] || s[b[x]] < s[i]) { b[x] = i; } } } void dfs2(int x, int y) { l[x] = y; L[x] = ss++; if (b[x] > 0) { dfs2(b[x], y); } for (int i: a[x]) { if (i != b[x]) { dfs2(i, i); } } R[x] = ss; } int main() { scanf("%d", &n); for (int i = 2; i <= n; i++) { scanf("%d", &x); a[x + 1].push_back(i); } dfs(1, 0); dfs2(1, 1); memset(sa, -1, sizeof sa); scanf("%d", &m); for (int i = 0; i < m; i++) { char o[20]; scanf("%s%d", o, &x); x++; int s = sm[1]; if (*o == 'i') { for (; x != 0; x = f[l[x]]) { change(1, 0, n, L[l[x]], L[x] + 1, 1); } printf("%d\n", sm[1] - s); } else { change(1, 0, n, L[x], R[x], 0); printf("%d\n", s - sm[1]); } } return 0; }
题解
维护一棵树,支持子树和链的操作。
树链剖分,然后求DFS序,先访问重链,这样重链在DFS序中是连续的。